He decidido comenzar un nuevo blog algo más dedicado al tema de la ciberseguridad y la privacidad así como vivencias y recuerdos «digitales».
El nuevo blog es www.fernandogonzalez.es

He decidido comenzar un nuevo blog algo más dedicado al tema de la ciberseguridad y la privacidad así como vivencias y recuerdos «digitales».
El nuevo blog es www.fernandogonzalez.es

Actualmente en la empresa, a diferencia que fuera de ella, las redes sociales no son tan comunes. Derivado de esta situación, no encontramos sistemas de ayuda al trabajador sobre determinadas acciones que puede realizar para ayudarse en su trabajo y, por tanto, de sistemas que propicien recomendaciones sobre la toma de decisiones. Por ejemplo, Facebook recomienda amigos o contactos derivados del conjunto de acciones y actividades desarrolladas por el usuario en esta red social.
Al igual que ha pasado con la llamada “gamificación” en la que se traslada la mecánica de los juegos al ámbito profesional con el fin de conseguir mejores resultados, el sistema de recomendaciones para facilitar determinadas acciones puede resultar en un gran beneficio para la productividad del trabajador.
Alfresco, como muchos sistemas de gestión documental usados como herramientas para la gestión del conocimiento, no tienen herramientas que analicen las relaciones establecidas entre las acciones que realizan los usuarios que usan estas aplicaciones. Por tanto, no pueden ofrecer sugerencias o indicaciones del trabajo que están realizando el resto de compañeros que tienen en el mismo departamento o que están solicitando o trabajando con la misma información.
MASCI es un sistema que añade un control donde se visualizan sugerencias sobre documentos que pueden ser de interés a un usuario según las relaciones que se han producido entre otros usuarios que tienen algún tipo de relación con él.
El sistema consiste en un módulo instalable para Alfresco y Share así como un middleware que realiza la conexión entre Alfresco y Neo4j.

El proyecto, en su primera fase, puede encontrarse en: https://gitlab.com/fegor/masci
![]() He publicado una nueva revisión de Alfviral (versión 1.4.0), con una reestructuración del código, con las siguientes características:
He publicado una nueva revisión de Alfviral (versión 1.4.0), con una reestructuración del código, con las siguientes características:
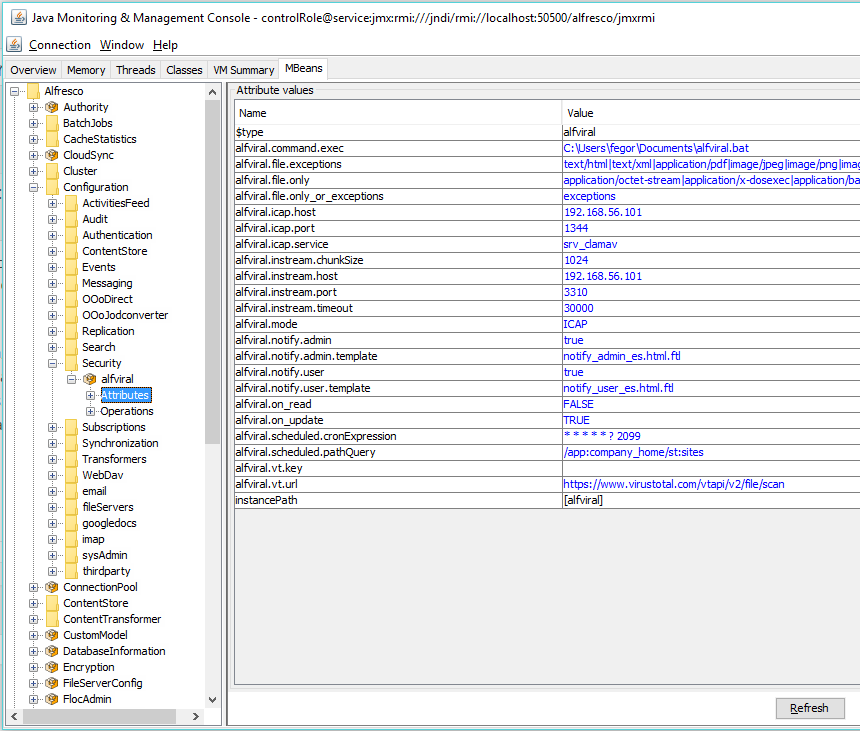
El código está en: https://github.com/fegorama/alfviral/releases/tag/v1.4.0-SNAPSHOT
 He liberado una nueva revisión de Alfviral que arreglaba algún problema en el modo COMMAND de menor importancia. La siguiente modificación que voy a hacer es crear el servicio como un subsistema de Alfresco para que pueda ser reconfigurado en caliente.
He liberado una nueva revisión de Alfviral que arreglaba algún problema en el modo COMMAND de menor importancia. La siguiente modificación que voy a hacer es crear el servicio como un subsistema de Alfresco para que pueda ser reconfigurado en caliente.
La nueva revisión está en https://github.com/fegorama/alfviral/releases/tag/v1.3.4-SNAPSHOT
 Este, creo, es el primer artículo, de este blog, en el que no voy a hablar de Alfresco. Resulta que estas vacaciones no sabía que hacer y he decidido rememorar los tiempos en los que me hacía mis juegos con el MSX, si, un poco de programación rápida, sin planear nada de ante mano y en unas 5 tardes. De hecho, comencé por mirar los gráficos AWT de Java ya que no tenía grandes pretensiones y casi en el momento empecé a escribir un programa que, en principio, iba a ser un algoritmo de parábola para una bolita, pero luego encontré por Internet un par de gráficos de navecitas así que, finalmente, he hecho un juego de naves.
Este, creo, es el primer artículo, de este blog, en el que no voy a hablar de Alfresco. Resulta que estas vacaciones no sabía que hacer y he decidido rememorar los tiempos en los que me hacía mis juegos con el MSX, si, un poco de programación rápida, sin planear nada de ante mano y en unas 5 tardes. De hecho, comencé por mirar los gráficos AWT de Java ya que no tenía grandes pretensiones y casi en el momento empecé a escribir un programa que, en principio, iba a ser un algoritmo de parábola para una bolita, pero luego encontré por Internet un par de gráficos de navecitas así que, finalmente, he hecho un juego de naves.
El juego es muy sencillo, derecha, izquierda, disparo y listo, los enemigos pueden usar 3 tipos de estrategia, una que sigue a la nave amiga, otro que de desplaza a la derecha y otra a la izquierda.
Solo he usado estos tres gráficos que pongo a continuación, que podéis descargar para usarlos:
Sobre los sonidos, he usado los siguientes, igualmente podéis usarlos:
Y nada más, a continuación os pongo el código fuente de cada fichero. No esperéis nada especial ni un código modelo dentro de la programación orientada a objetos, lo he ido escribiendo sobre la marcha para hacerlo en eso, cinco tardes de verano.
Fichero: Enemy.java
package com.fegor.games.parabolic;
import java.awt.Graphics;
import java.util.ArrayList;
/**
* @author fegor
*
*/
public class Enemy implements Trace {
private final int STRATEGY_RIGHT = 0;
private final int STRATEGY_LEFT = 1;
private final int STRATEGY_PERSECUTION = 2;
private final int MAX_ENEMY = 7;
private Graphics gr = null;
private int enemies;
private ArrayList<Sprite> enemy;
private ArrayList<Sprite> laserEnemy;
private ArrayList<Boolean> shootLaser;
private ArrayList<Sound> soundLaser;
private ArrayList<Sound> soundExplotion;
private ArrayList<Integer> strategy;
private ArrayList<Boolean> isAlive;
private int screen_width = 480;
private int screen_height = 640;
/**
*
*/
public Enemy() {
enemy = new ArrayList<Sprite>();
laserEnemy = new ArrayList<Sprite>();
shootLaser = new ArrayList<Boolean>();
soundLaser = new ArrayList<Sound>();
soundExplotion = new ArrayList<Sound>();
strategy = new ArrayList<Integer>();
isAlive = new ArrayList<Boolean>();
initEnemies();
}
/**
*
*/
public void draw() {
for (int i = 0; i < MAX_ENEMY; i++) {
if (isAlive.get(i)) {
enemy.get(i).setGr(gr);
enemy.get(i).draw();
}
if (shootLaser.get(i)) {
laserEnemy.get(i).setGr(gr);
laserEnemy.get(i).draw();
}
}
}
/**
* @param targetX
* @param targetDistance
*/
public void refreshPosition(int targetX, int targetDistance) {
for (int i = 0; i < MAX_ENEMY; i++) {
// move from strategy
if (isAlive.get(i) && strategy.get(i) == STRATEGY_RIGHT) {
if (enemy.get(i).getX() > screen_width)
enemy.get(i).setX(0);
enemy.get(i).moveRight();
}
else if (isAlive.get(i) && strategy.get(i) == STRATEGY_LEFT) {
if (enemy.get(i).getX() == 0)
enemy.get(i).setX(screen_width);
enemy.get(i).moveLeft();
}
else if (isAlive.get(i) && strategy.get(i) >= STRATEGY_PERSECUTION) {
if (enemy.get(i).getX() < (targetX - targetDistance))
enemy.get(i).moveRight();
else if (enemy.get(i).getX() > (targetX + targetDistance))
enemy.get(i).moveLeft();
}
// down
if (isAlive.get(i) && enemy.get(i).getY() > screen_height - (enemy.get(i).getHeight() * 2)) {
enemyDestroy(i);
}
else if (isAlive.get(i))
if ((i == 0) || ((i > 0 && (enemy.get(i - 1).getY() > (32 * 2)))) || (!isAlive.get(i - 1))) {
enemy.get(i).moveDown();
}
}
// all enemies dead?
if (enemies <= 0)
enemiesReset();
}
/**
*
*/
public void shoot() {
for (int i = 0; i < MAX_ENEMY; i++) {
if ((!shootLaser.get(i)) && isAlive.get(i))
if (((int) (Math.random() * 99)) == 0) {
shootLaser.set(i, true);
soundLaser.get(i).play();
}
if (shootLaser.get(i)) {
if (laserEnemy.get(i).getX() == 0) {
laserEnemy.get(i).setX(enemy.get(i).getX() + (enemy.get(i).getWidth() / 2));
laserEnemy.get(i).setY(enemy.get(i).getY() + (enemy.get(i).getHeight()));
}
if (shootLaser.get(i) && (laserEnemy.get(i).getY() < screen_height - laserEnemy.get(i).getHeight()))
laserEnemy.get(i).moveDown();
else {
laserEnemy.get(i).setX(0);
shootLaser.set(i, false);
}
}
}
}
/**
* @param s
* @return
*/
public boolean collition(Sprite s) {
boolean res = false;
for (int i = 0; i < MAX_ENEMY; i++) {
if (isAlive.get(i) && enemy.get(i).hasCollition(s)) {
soundExplotion.get(i).play();
res = true;
enemyDestroy(i);
if (isTrace)
System.out.println("Collition enemy " + i + " to " + s.getName());
}
}
return res;
}
/**
* @param s
* @return
*/
public boolean laserCollition(Sprite s) {
boolean res = false;
for (int i = 0; i < MAX_ENEMY; i++) {
if (shootLaser.get(i) && laserEnemy.get(i).hasCollition(s)) {
res = true;
laserDestroy(i);
if (isTrace)
System.out.println("Collition laser " + i + " to " + s.getName());
}
}
return res;
}
/**
*
*/
private void initEnemies() {
// Create enemies, laser and soundss
for (int i = 0; i < MAX_ENEMY; i++) {
enemy.add(new Sprite());
isAlive.add(true);
laserEnemy.add(new Sprite());
laserEnemy.get(i).setMoveStepY(10);
shootLaser.add(false);
soundLaser.add(new Sound("laser_shot2.wav"));
soundExplotion.add(new Sound("explosion2.wav"));
strategy.add(null);
enemy.get(i).addImage("nave_verde32.png");
laserEnemy.get(i).addImage("laser32.png");
}
enemiesReset();
}
/**
* @param e
* @param i
*/
private void reset(Sprite e, int i) {
e.setX((screen_width / MAX_ENEMY) * i);
e.setY(32);
e.setMoveStepX(1);
}
/**
*
*/
private void enemiesReset() {
if (isTrace)
System.out.println("Enemies reset");
for (int i = 0; i < MAX_ENEMY; i++) {
reset(enemy.get(i), i);
strategy.set(i, (int) (Math.random() * 3));
isAlive.set(i, true);
}
enemies = MAX_ENEMY;
}
/**
* @param i
*/
private void enemyDestroy(int i) {
isAlive.set(i, false);
enemies--;
}
/**
* @param i
*/
private void laserDestroy(int i) {
shootLaser.set(i, false);
}
/**
* @param gr
*/
public void setGr(Graphics gr) {
this.gr = gr;
}
/**
* @param screen_width
*/
public void setScreen_width(int screen_width) {
this.screen_width = screen_width;
}
/**
* @param screen_height
*/
public void setScreen_height(int screen_height) {
this.screen_height = screen_height;
}
/**
* @return
*/
public ArrayList<Boolean> getIsAlive() {
return isAlive;
}
/**
* @param isAlive
*/
public void setIsAlive(ArrayList<Boolean> isAlive) {
this.isAlive = isAlive;
}
/**
* @return
*/
public int getEnemies() {
return enemies;
}
/**
* @param enemies
*/
public void setEnemies(int enemies) {
this.enemies = enemies;
}
/**
* @return
*/
public ArrayList<Boolean> getShootLaser() {
return shootLaser;
}
/**
* @return
*/
public ArrayList<Sound> getSoundLaser() {
return soundLaser;
}
}
Fichero: Game.java
package com.fegor.games.parabolic;
import java.awt.Color;
import java.awt.Font;
import java.awt.Graphics;
import java.awt.Graphics2D;
import java.awt.Toolkit;
import java.awt.event.KeyEvent;
import java.awt.event.KeyListener;
import java.util.ArrayList;
import javax.swing.JPanel;
/**
* @author fegor
*
*/
public class Game extends JPanel implements Runnable, Trace {
private static final long serialVersionUID = -3239737141818043435L;
private static final int STARSHIPS_COLLITION = 1;
private static final int STARSHIPBLUE_LOSS = 2;
private static final int STARSHIPGREEN_LOSS = 3;
private static final int INIT_DELAY = 30;
private static final int SCREEN_WIDTH = 480;
private static final int SCREEN_HEIGHT = 640;
private static final int MAX_STARS = 100;
private static final int NUM_STARSHIPS = 5;
private int delay = INIT_DELAY;
private Color colorTextBlink;
private int score = 0;
private int numStarShips = NUM_STARSHIPS;
private boolean shootStarShipBlue = false;
private boolean isGameOver = false;
private boolean isWaitStart = true;
private int dx;
private Enemy enemy;
private Sprite starShipBlue;
private Sprite laserStarShipBlue;
private Sound soundLaserBlue;
private Sound soundExplosionBlue;
private Sound soundReadyGo;
private Sound soundGameOver;
private ArrayList<Star> stars = new ArrayList<Star>();
private int moveStars = 0;
private int distance = 10;
private Thread thread;
/**
*
*/
public Game() {
setBackground(Color.BLACK);
setDoubleBuffered(true);
enemy = new Enemy();
enemy.setScreen_width(SCREEN_WIDTH);
enemy.setScreen_height(SCREEN_HEIGHT);
starShipBlue = new Sprite();
starShipBlue.addImage("nave_azul32.png");
resetStarShipBlue();
laserStarShipBlue = new Sprite();
laserStarShipBlue.addImage("laser32.png");
laserStarShipBlue.setMoveStepY(10);
soundReadyGo = new Sound("ready_go.wav");
soundGameOver = new Sound("game_over.wav");
soundLaserBlue = new Sound("laser_shot2.wav");
soundExplosionBlue = new Sound("explosion2.wav");
// Generate stars
int nColor;
for (int i = 0; i < MAX_STARS; i++) {
nColor = (int) (Math.random() * 256 - 1);
Color color = new Color(nColor, nColor, nColor);
stars.add(new Star((int) (Math.random() * SCREEN_WIDTH - 1),
(int) (Math.random() * (SCREEN_HEIGHT - 1 + 32)), color));
}
}
/* (non-Javadoc)
* @see java.lang.Runnable#run()
*/
@Override
public void run() {
while (true) {
if (isWaitStart) {
colorTextBlink = (colorTextBlink == Color.GREEN ? Color.BLACK : Color.GREEN);
repaint();
try {
Thread.sleep(300);
}
catch (InterruptedException ie) {
System.out.println(ie);
}
}
else if (isGameOver) {
colorTextBlink = (colorTextBlink == Color.GREEN ? Color.BLACK : Color.GREEN);
repaint();
try {
Thread.sleep(300);
}
catch (InterruptedException ie) {
System.out.println(ie);
}
}
else {
loop();
repaint();
try {
Thread.sleep(delay);
}
catch (InterruptedException ie) {
System.out.println(ie);
}
}
}
}
/**
*
*/
private void resetGame() {
delay = INIT_DELAY;
score = 0;
numStarShips = NUM_STARSHIPS;
resetStarShipBlue();
enemy = null;
enemy = new Enemy();
}
/**
*
*/
private void resetStarShipBlue() {
starShipBlue.setX((SCREEN_WIDTH + starShipBlue.getWidth()) / 2);
starShipBlue.setY(SCREEN_HEIGHT - (starShipBlue.getHeight() * 2));
starShipBlue.setMoveStepX(5);
}
/**
*
*/
private void resetLaserStarShipBlue() {
laserStarShipBlue.setX(-32);
laserStarShipBlue.setY(-32);
shootStarShipBlue = false;
}
/* (non-Javadoc)
* @see javax.swing.JComponent#addNotify()
*/
@Override
public void addNotify() {
super.addNotify();
thread = new Thread(this);
thread.start();
}
/* (non-Javadoc)
* @see javax.swing.JComponent#paint(java.awt.Graphics)
*/
@Override
public void paint(Graphics g) {
super.paint(g);
Graphics2D g2d = (Graphics2D) g;
if (isGameOver) {
g.setColor(Color.GREEN);
g.setFont(new Font("Monospaced", Font.BOLD, 40));
g.drawString("GAME OVER", (SCREEN_WIDTH / 2) - (3 * 40), SCREEN_HEIGHT / 2);
g.setFont(new Font("Monospaced", Font.BOLD, 26));
g.drawString("SCORE: " + score, (SCREEN_WIDTH / 2) - (5 * 26), (SCREEN_HEIGHT / 2) + 120);
g.setColor(colorTextBlink);
g.drawString("PRESS S TO BEGIN", (SCREEN_WIDTH / 2) - (5 * 26), (SCREEN_HEIGHT / 2) + 60);
}
else if (isWaitStart) {
g.setColor(Color.GREEN);
g.setFont(new Font("Monospaced", Font.BOLD, 30));
g.drawString("PARABOLIC STARSHIPS", (SCREEN_WIDTH / 2) - (6 * 30), (SCREEN_HEIGHT / 2));
g.setColor(colorTextBlink);
g.setFont(new Font("Monospaced", Font.BOLD, 20));
g.drawString("PRESS S TO BEGIN", (SCREEN_WIDTH / 2) - (5 * 20), (SCREEN_HEIGHT / 2) + 60);
}
else {
g.setColor(Color.GREEN);
g.setFont(new Font("Monospaced", Font.BOLD, 20));
g.drawString("LIVES: " + numStarShips, 10, 16);
g.drawString("LEVEL: " + ((INIT_DELAY + 1) - delay), (SCREEN_WIDTH / 2) - (3 * 20), 16);
g.drawString("SCORE: " + score, SCREEN_WIDTH - (7 * 20), 16);
for (int i = 0; i < MAX_STARS; i++) {
g.setColor(stars.get(i).getColor());
stars.get(i).setGr(g2d);
stars.get(i).draw();
}
if (enemy.getEnemies() == 0 && delay > 5)
delay--;
enemy.setGr(g2d);
enemy.draw();
starShipBlue.setGr(g2d);
starShipBlue.draw();
if (shootStarShipBlue) {
laserStarShipBlue.setGr(g2d);
laserStarShipBlue.draw();
}
}
Toolkit.getDefaultToolkit().sync();
g.dispose();
}
/**
*
*/
public void loop() {
int i;
moveShipBlue();
// stars move
if (moveStars == 5) {
for (i = 1; i < MAX_STARS; i++) {
if (stars.get(i).getY() < SCREEN_HEIGHT)
stars.get(i).setY(stars.get(i).getY() + 1);
else {
stars.get(i).setX((int) (Math.random() * (SCREEN_WIDTH - 1)));
stars.get(i).setY(32);
}
}
moveStars = 0;
}
else
moveStars++;
// enemy move
enemy.refreshPosition(starShipBlue.getX(), distance);
// Laser of starship blue
if (shootStarShipBlue) {
if (laserStarShipBlue.getX() == -32) {
laserStarShipBlue.setX(starShipBlue.getX() + (starShipBlue.getWidth() / 2));
laserStarShipBlue.setY(starShipBlue.getY() - (starShipBlue.getHeight()));
}
if (laserStarShipBlue.getY() > 32)
laserStarShipBlue.moveUp();
else
resetLaserStarShipBlue();
}
// Laser of enemies
enemy.shoot();
// Collitions
if (enemy.collition(starShipBlue)) {
managerCollition(STARSHIPS_COLLITION);
}
else if (enemy.collition(laserStarShipBlue)) {
managerCollition(STARSHIPGREEN_LOSS);
}
else if (enemy.laserCollition(starShipBlue)) {
managerCollition(STARSHIPBLUE_LOSS);
}
}
/**
* @param status
*/
private void managerCollition(int status) {
if (status == STARSHIPS_COLLITION || status == STARSHIPBLUE_LOSS) {
if (numStarShips > 0) {
if (status == STARSHIPS_COLLITION) {
soundExplosionBlue.play();
resetStarShipBlue();
}
else {
soundExplosionBlue.play();
resetStarShipBlue();
}
numStarShips--;
}
else {
soundGameOver.play();
isGameOver = true;
if (isTrace)
System.out.println("Game Over");
}
}
else if (status == STARSHIPGREEN_LOSS) {
score++;
resetLaserStarShipBlue();
}
}
/**
* @return
*/
public int getScreenWidth() {
return SCREEN_WIDTH;
}
/**
* @return
*/
public int getScreenHeight() {
return SCREEN_HEIGHT;
}
/**
*
*/
private void moveShipBlue() {
int x = starShipBlue.getX();
if (x > 1 && dx == -1)
starShipBlue.moveLeft();
else if (x < (SCREEN_WIDTH - starShipBlue.getWidth()) && dx == 1)
starShipBlue.moveRight();
}
/**
* @return
*/
public KeyListener keyboardControl() {
KeyListener keyListener = new KeyListener() {
@Override
public void keyPressed(KeyEvent e) {
int c = e.getKeyCode();
switch (c) {
case KeyEvent.VK_LEFT:
dx = -1;
break;
case KeyEvent.VK_RIGHT:
dx = 1;
break;
case KeyEvent.VK_S:
if (isWaitStart) {
soundReadyGo.play();
isWaitStart = false;
if (isTrace)
System.out.println("Start");
}
else if (isGameOver) {
soundReadyGo.play();
resetGame();
isGameOver = false;
if (isTrace)
System.out.println("Start");
}
break;
case KeyEvent.VK_SPACE:
if (!shootStarShipBlue) {
shootStarShipBlue = true;
soundLaserBlue.play();
}
break;
default:
break;
}
repaint();
}
/**
* @param e
*/
@Override
public void keyReleased(KeyEvent e) {
int c = e.getKeyCode();
switch (c) {
case KeyEvent.VK_LEFT:
dx = 0;
break;
case KeyEvent.VK_RIGHT:
dx = 0;
break;
default:
break;
}
}
/**
* @param e
*/
@Override
public void keyTyped(KeyEvent e) {
// TODO Auto-generated method stub
}
};
return keyListener;
}
}
Fichero: Main.java
package com.fegor.games.parabolic;
import javax.swing.JFrame;
/**
* @author fegor
*
*/
public class Main extends JFrame {
private static final long serialVersionUID = 1L;
/**
*
*/
public Main() {
Game game = new Game();
setTitle("Naves");
setDefaultCloseOperation(EXIT_ON_CLOSE);
setSize(game.getScreenWidth(), game.getScreenHeight());
setLocationRelativeTo(null);
setResizable(false);
add(game);
addKeyListener(game.keyboardControl());
setFocusable(true);
setVisible(true);
}
/**
* @param args
*/
public static void main(String args[]) {
new Main();
}
}
Fichero: Sound.java
package com.fegor.games.parabolic;
import java.io.BufferedInputStream;
import java.io.IOException;
import javax.sound.sampled.AudioFormat;
import javax.sound.sampled.AudioInputStream;
import javax.sound.sampled.AudioSystem;
import javax.sound.sampled.Clip;
import javax.sound.sampled.DataLine;
import javax.sound.sampled.LineUnavailableException;
import javax.sound.sampled.SourceDataLine;
/**
* @author fegor
*
*/
public class Sound implements Runnable {
Thread thread;
String soundFile;
BufferedInputStream bs;
AudioInputStream ais;
Clip clip;
/**
* @param soundFile
*/
public Sound(String soundFile) {
this.soundFile = soundFile;
}
/**
*
*/
public void play() {
thread = new Thread(this);
thread.start();
}
/* (non-Javadoc)
* @see java.lang.Runnable#run()
*/
/* (non-Javadoc)
* @see java.lang.Runnable#run()
*/
@Override
public void run() {
try {
if (bs != null) {
return;
}
bs = new BufferedInputStream(
Sound.class.getResourceAsStream("/com/fegor/games/parabolic/resources/" + soundFile));
ais = AudioSystem.getAudioInputStream(bs);
final int BUFFER_SIZE = 128000;
SourceDataLine sourceLine = null;
AudioFormat audioFormat = ais.getFormat();
DataLine.Info info = new DataLine.Info(SourceDataLine.class, audioFormat);
sourceLine = (SourceDataLine) AudioSystem.getLine(info);
sourceLine.open(audioFormat);
sourceLine.start();
int nBytesRead = 0;
byte[] abData = new byte[BUFFER_SIZE];
while (nBytesRead != -1) {
try {
nBytesRead = bs.read(abData, 0, abData.length);
} catch (IOException e) {
e.printStackTrace();
}
if (nBytesRead >= 0) {
sourceLine.write(abData, 0, nBytesRead);
}
}
sourceLine.drain();
sourceLine.close();
bs.close();
bs.close();
bs = null;
}
catch (IOException e) {
e.printStackTrace();
}
catch (LineUnavailableException e) {
e.printStackTrace();
System.exit(1);
}
catch (Exception e) {
e.printStackTrace();
System.exit(1);
}
}
}
Fichero: Sprite.java
package com.fegor.games.parabolic;
import java.awt.Graphics;
import java.awt.Image;
import java.awt.Rectangle;
import java.awt.image.BufferedImage;
import java.awt.image.ImageObserver;
import java.net.URL;
import java.util.ArrayList;
import javax.imageio.ImageIO;
/**
* @author fegor
*
*/
public class Sprite implements ImageObserver {
private int x;
private int y;
private int width;
private int height;
private int nImage;
private int moveStepX;
private int moveStepY;
private String name;
private ArrayList<BufferedImage> alImage = new ArrayList<BufferedImage>();
private Graphics gr = null;
/**
*
*/
public Sprite() {
x = 0;
y = 0;
width = 16;
height = 16;
nImage = 0;
moveStepX = 1;
moveStepY = 1;
name = null;
}
/**
*
*/
public void moveRight() {
x += moveStepX;
}
/**
*
*/
public void moveLeft() {
x -= moveStepX;
}
/**
*
*/
public void moveUp() {
y -= moveStepY;
}
/**
*
*/
public void moveDown() {
y += moveStepY;
}
/**
*
*/
public void draw() {
if (gr == null)
System.out.println("Not graphics found for visualize sprite");
else {
if (nImage < alImage.size())
nImage = 0;
else
nImage++;
gr.drawImage(alImage.get(nImage), x, y, (ImageObserver) this);
}
}
/**
* @param img
*/
public void addImage(String img) {
if (name == null)
name = img;
alImage.add(loadImage(img));
}
/**
* @param image
* @return
*/
private BufferedImage loadImage(String image) {
BufferedImage bi = null;
try {
URL url = Sprite.class.getResource("/com/fegor/games/parabolic/resources/" + image);
bi = ImageIO.read(url);
this.width = bi.getWidth();
this.height = bi.getHeight();
return bi;
}
catch (Exception e) {
System.out.println("Image not found");
return null;
}
}
/**
* @return
*/
public int getX() {
return x;
}
/**
* @param x
*/
public void setX(int x) {
this.x = x;
}
/**
* @return
*/
public int getY() {
return y;
}
/**
* @param y
*/
public void setY(int y) {
this.y = y;
}
/**
* @return
*/
public int getWidth() {
return width;
}
/**
* @param width
*/
public void setWidth(int width) {
this.width = width;
}
/**
* @return
*/
public int getHeight() {
return height;
}
/**
* @param height
*/
public void setHeight(int height) {
this.height = height;
}
/**
* @param gr
*/
public void setGr(Graphics gr) {
this.gr = gr;
}
/**
* @param moveStepX
*/
public void setMoveStepX(int moveStepX) {
this.moveStepX = moveStepX;
}
/**
* @param moveStepY
*/
public void setMoveStepY(int moveStepY) {
this.moveStepY = moveStepY;
}
/* (non-Javadoc)
* @see java.awt.image.ImageObserver#imageUpdate(java.awt.Image, int, int, int, int, int)
*/
@Override
public boolean imageUpdate(Image img, int infoflags, int x, int y, int width, int height) {
System.out.println("imageUpdate");
return false;
}
/**
* @return
*/
public Rectangle getBounds() {
return new Rectangle(x, y, width, height);
}
/**
* @param s
* @return
*/
public boolean hasCollition(Sprite s) {
return s.getBounds().intersects(getBounds());
}
/**
* @return
*/
public String getName() {
return name;
}
/**
* @param name
*/
public void setName(String name) {
this.name = name;
}
}
Fichero: Star.java
package com.fegor.games.parabolic;
import java.awt.Color;
import java.awt.Graphics;
/**
* @author fegor
*
*/
public class Star {
int x, y;
Color color;
private Graphics gr = null;
/**
* @param x
* @param y
* @param color
*/
public Star(int x, int y, Color color) {
this.x = x;
this.y = y;
this.color = color;
}
/**
*
*/
public void draw() {
if (gr == null)
System.out.println("Not graphics found for visualize sprite");
else
gr.drawLine(x, y, x, y);
}
/**
* @return
*/
public int getX() {
return x;
}
/**
* @param x
*/
public void setX(int x) {
this.x = x;
}
/**
* @return
*/
public int getY() {
return y;
}
/**
* @param y
*/
public void setY(int y) {
this.y = y;
}
/**
* @return
*/
public Color getColor() {
return color;
}
/**
* @param color
*/
public void setColor(Color color) {
this.color = color;
}
/**
* @param gr
*/
public void setGr(Graphics gr) {
this.gr = gr;
}
}
Fichero: Trace.java
package com.fegor.games.parabolic;
/**
* @author fegor
*
*/
public interface Trace {
public static final Boolean TRON = true;
public static final Boolean TROFF = false;
public static Boolean isTrace = TRON;
}
¡FELIZ VERANO!
Scala es un lenguaje multi-paradigma que integra características de lenguajes funcionales y orientados a objetos, al contrario que Java que es un lenguaje imperativo (excepto en la versión 8 que Oracle ha incluido algunas características de lenguaje funcional como las funciones lambda).
Por tanto, es una buena idea poder utilizar Scala y Java en Alfresco ya que, de esta forma, podemos tener los dos paradigmas –funcional e imperativo– a nuestro servicio.
La prueba se ha realizado sobre Alfresco 5.0.c y se ha utilizado maven con el arquetipo de creación de módulos AMP, versión 2.2.0 del SDK.
Los siguientes componentes son recomendables para poder utilizar Scala en Eclipse IDE:
– Instalar desde Marketplace: Scala IDE 4.2.x (recomendable)
– Instalar desde «Install new software» (opcional):
Nombre: Maven for Scala
URL: http://alchim31.free.fr/m2e-scala/update-site/
mvn archetype:generate -Dfilter=org.alfresco: [INFO] Scanning for projects... [INFO] [INFO] ------------------------------------------------------------------------ [INFO] Building Maven Stub Project (No POM) 1 [INFO] ------------------------------------------------------------------------ [INFO] [INFO] >>> maven-archetype-plugin:2.2:generate (default-cli) > generate-sources @ standalone-pom >>> [INFO] [INFO] <<< maven-archetype-plugin:2.2:generate (default-cli) < generate-sources @ standalone-pom <<< [INFO] [INFO] --- maven-archetype-plugin:2.2:generate (default-cli) @ standalone-pom -- - [INFO] Generating project in Interactive mode [INFO] No archetype defined. Using maven-archetype-quickstart (org.apache.maven. archetypes:maven-archetype-quickstart:1.0) Choose archetype: 1: remote -> org.alfresco.maven.archetype:alfresco-allinone-archetype (Sample mu lti-module project for All-in-One development on the Alfresco plaftorm. Includes modules for: Repository WAR overlay, Repository AMP, Share WAR overlay, Solr co nfiguration, and embedded Tomcat runner) 2: remote -> org.alfresco.maven.archetype:alfresco-amp-archetype (Sample project with full support for lifecycle and rapid development of Repository AMPs (Alfre sco Module Packages)) 3: remote -> org.alfresco.maven.archetype:share-amp-archetype (Share project wit h full support for lifecycle and rapid development of AMPs (Alfresco Module Packages)) Choose a number or apply filter (format: [groupId:]artifactId, case sensitive co ntains): : 2 Choose org.alfresco.maven.archetype:alfresco-amp-archetype version: 1: 2.0.0-beta-1 2: 2.0.0-beta-2 3: 2.0.0-beta-3 4: 2.0.0-beta-4 5: 2.0.0 6: 2.1.0 7: 2.1.1 8: 2.2.0 Choose a number: 8: 8 Downloading: https://repo.maven.apache.org/maven2/org/alfresco/maven/archetype/a lfresco-amp-archetype/2.2.0/alfresco-amp-archetype-2.2.0.jar Downloaded: https://repo.maven.apache.org/maven2/org/alfresco/maven/archetype/al fresco-amp-archetype/2.2.0/alfresco-amp-archetype-2.2.0.jar (26 KB at 16.2 KB/se c) Downloading: https://repo.maven.apache.org/maven2/org/alfresco/maven/archetype/a lfresco-amp-archetype/2.2.0/alfresco-amp-archetype-2.2.0.pom Downloaded: https://repo.maven.apache.org/maven2/org/alfresco/maven/archetype/al fresco-amp-archetype/2.2.0/alfresco-amp-archetype-2.2.0.pom (3 KB at 16.3 KB/sec ) Define value for property 'groupId': : com.fegor.alfresco.scala Define value for property 'artifactId': : AlfScala [INFO] Using property: version = 1.0-SNAPSHOT Define value for property 'package': com.fegor.alfresco.scala: : Confirm properties configuration: groupId: com.fegor.alfresco.scala artifactId: AlfScala version: 1.0-SNAPSHOT package: com.fegor.alfresco.scala Y: :
Crear los directorios para trabajar con Scala dentro del proyecto:
src/main/scala src/test/scala
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.fegorsoft.alfresco.scala</groupId>
<artifactId>AlfScala</artifactId>
<version>1.0-SNAPSHOT</version>
<name>AlfScala Repository AMP project</name>
<packaging>amp</packaging>
<description>Manages the lifecycle of the AlfScala Repository AMP (Alfresco Module Package)</description>
<parent>
<groupId>org.alfresco.maven</groupId>
<artifactId>alfresco-sdk-parent</artifactId>
<version>2.2.0</version>
</parent>
<repositories>
<repository>
<id>artima</id>
<name>Artima Maven Repository</name>
<url>http://repo.artima.com/releases</url>
</repository>
</repositories>
<!--
SDK properties have sensible defaults in the SDK parent,
but you can override the properties below to use another version.
For more available properties see the alfresco-sdk-parent POM.
-->
<properties>
<!-- The following are default values for data location and Alfresco Community version.
Uncomment if you need to change (Note. current default version for Enterprise edition is 5.1)
<alfresco.version>5.1.e</alfresco.version>
<alfresco.data.location>/absolute/path/to/alf_data_dev</alfresco.data.location> -->
<!-- This control the root logging level for all apps uncomment and change, defaults to WARN
<app.log.root.level>WARN</app.log.root.level>
-->
<!-- Set the enviroment to use, this controls which properties will be picked in src/test/properties
for embedded run, defaults to the 'local' environment. See SDK Parent POM for more info.
<env>local</env>
-->
<recompileMode>incremental</recompileMode>
<fsc>false</fsc>
</properties>
<!-- Here we realize the connection with the Alfresco selected platform
(e.g.version and edition) -->
<dependencyManagement>
<dependencies>
<!-- Setup what versions of the different Alfresco artifacts that will be used (depends on alfresco.version),
so we don't have to specify version in any of the dependency definitions in our POM.
For more info see:
http://maven.apache.org/guides/introduction/introduction-to-dependency-mechanism.html#Importing_Dependencies
-->
<dependency>
<groupId>${alfresco.groupId}</groupId>
<artifactId>alfresco-platform-distribution</artifactId>
<version>${alfresco.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Following dependencies are needed for compiling Java code in src/main/java;
<scope>provided</scope> is inherited for each of the following;
for more info, please refer to alfresco-platform-distribution POM -->
<dependency>
<groupId>${alfresco.groupId}</groupId>
<artifactId>alfresco-repository</artifactId>
</dependency>
<!-- If we are running tests then make the H2 Scripts available
Note. tests are skipped when you are running -Pamp-to-war -->
<dependency>
<groupId>${alfresco.groupId}</groupId>
<artifactId>alfresco-repository</artifactId>
<version>${alfresco.version}</version>
<classifier>h2scripts</classifier>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>*</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.8</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>com.typesafe.scala-logging</groupId>
<artifactId>scala-logging-slf4j_2.11</artifactId>
<version>2.1.2</version>
</dependency>
<dependency>
<groupId>org.scala-lang.modules</groupId>
<artifactId>scala-xml_2.11</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>org.scalactic</groupId>
<artifactId>scalactic_2.11</artifactId>
<version>3.0.0-M15</version>
</dependency>
<dependency>
<groupId>org.scalatest</groupId>
<artifactId>scalatest_2.11</artifactId>
<version>3.0.0-M15</version>
<scope>test</scope>
</dependency>
<!--
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
-->
</dependencies>
<profiles>
<!--
Brings in the extra Enterprise specific repository classes,
if the 'enterprise' profile has been activated, needs to be activated manually.
-->
<profile>
<id>enterprise</id>
<dependencies>
<dependency>
<groupId>${alfresco.groupId}</groupId>
<artifactId>alfresco-enterprise-repository</artifactId>
<version>${alfresco.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
</profile>
</profiles>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.1</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.0.2</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<inherited>true</inherited>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<!-- Run scala compiler in the process-resources phase, so that dependencies on
scala classes can be resolved later in the (Java) compile phase -->
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
<!-- Run scala compiler in the process-test-resources phase, so that dependencies on
scala classes can be resolved later in the (Java) test-compile phase -->
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<executions>
<!-- Add src/main/scala to source path of Eclipse -->
<execution>
<id>add-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>src/main/scala</source>
</sources>
</configuration>
</execution>
<!-- Add src/test/scala to test source path of Eclipse -->
<execution>
<id>add-test-source</id>
<phase>generate-test-sources</phase>
<goals>
<goal>add-test-source</goal>
</goals>
<configuration>
<sources>
<source>src/test/scala</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>
<!-- to generate Eclipse artifacts for projects mixing Scala and Java -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<version>2.8</version>
<configuration>
<downloadSources>true</downloadSources>
<downloadJavadocs>true</downloadJavadocs>
<projectnatures>
<projectnature>org.scala-ide.sdt.core.scalanature</projectnature>
<projectnature>org.eclipse.jdt.core.javanature</projectnature>
</projectnatures>
<buildcommands>
<buildcommand>org.scala-ide.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<classpathContainers>
<classpathContainer>org.scala-ide.sdt.launching.SCALA_CONTAINER</classpathContainer>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
</classpathContainers>
<excludes>
<!-- in Eclipse, use scala-library, scala-compiler from the SCALA_CONTAINER rather than POM <dependency> -->
<exclude>org.scala-lang:scala-library</exclude>
<exclude>org.scala-lang:scala-compiler</exclude>
</excludes>
<sourceIncludes>
<sourceInclude>**/*.scala</sourceInclude>
<sourceInclude>**/*.java</sourceInclude>
</sourceIncludes>
</configuration>
</plugin>
<!-- When run tests in the test phase, include .java and .scala source files -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<includes>
<include>**/*.java</include>
<include>**/*.scala</include>
</includes>
</configuration>
</plugin>
</plugins>
</build>
</project>
En este caso se crea una prueba unitaria para recuperar el contenido que hay dentro de ‘Company Home’.
package com.fegor.alfresco.scala.test
/*
* @author Fernando González (fegor at fegor dot com)
*
*/
import org.scalatest.junit.AssertionsForJUnit
import org.slf4j.LoggerFactory
import com.typesafe.scalalogging.slf4j.Logger
import org.junit.Assert._
import org.junit.{ Test, Before }
import org.junit.runner.RunWith
import com.tradeshift.test.remote.{ Remote, RemoteTestRunner }
import org.springframework.test.context.ContextConfiguration
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner
import org.springframework.context.ApplicationContext
import org.springframework.beans.factory.annotation.{ Autowired, Qualifier }
import org.alfresco.util.ApplicationContextHelper
import org.alfresco.model.ContentModel
import org.alfresco.service.cmr.repository.{ StoreRef, NodeService }
import org.alfresco.service.cmr.search.{ SearchService, ResultSet }
import org.alfresco.repo.security.authentication.AuthenticationUtil
/** Test Alfresco in Scala
*
* @constructor create tests for Alfresco with Scala
*/
@RunWith(classOf[RemoteTestRunner])
@Remote(runnerClass = classOf[SpringJUnit4ClassRunner])
@ContextConfiguration(Array("classpath:alfresco/application-context.xml"))
class RepositoryTest extends AssertionsForJUnit {
val logger = Logger(LoggerFactory.getLogger(classOf[RepositoryTest]))
val storeRef: StoreRef = new StoreRef(StoreRef.PROTOCOL_WORKSPACE, "SpacesStore")
val ctx: ApplicationContext = ApplicationContextHelper.getApplicationContext
val nodeService: NodeService = ctx.getBean("NodeService").asInstanceOf[NodeService]
var searchService: SearchService = ctx.getBean("SearchService").asInstanceOf[SearchService]
/* Initialize
*/
@Before
def initialize() {
AuthenticationUtil.setFullyAuthenticatedUser("admin")
}
/* Alfresco repository test
*/
@Test
def testRepositoryList() {
val rs: ResultSet = searchService.query(storeRef, SearchService.LANGUAGE_LUCENE, "PATH:\"/app:company_home/*\"")
assert(rs.length() > 0)
logger.info((for (i <- 0 until rs.length()) yield nodeService.getProperty(rs.getNodeRef(i), ContentModel.PROP_NAME)) mkString ",")
rs.close()
}
}
log4j.logger.com.fegor.alfresco.scala.test.RepositoryTest=DEBUG
2016-03-30 21:23:09,884 INFO [extensions.webscripts.ScriptProcessorRegistry] [main] Registered script processor javascript for extension js 2016-03-30 21:23:10,165 INFO [scala.test.RepositoryTest] [main] Guest Home,User Homes,Shared,Imap Attachments,IMAP Home,Sites,Data Dictionary Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 41.923 sec - in com.fegor.alfresco.scala.test.RepositoryTest
http://scala-ide.org/docs/tutorials/m2eclipse/index.html
http://www.scalatest.org/getting_started_with_junit_4_in_scala
http://ted-gao.blogspot.com.es/2011/09/mixing-scala-and-java-in-project.html
https://en.wikipedia.org/wiki/Scala_(programming_language)
https://es.wikipedia.org/wiki/Scala_(lenguaje_de_programaci%C3%B3n)
![]() Desde Java se puede acceder al servicio de bloqueo de nodos de Alfresco, pero desde JScript (WebScripts) no se puede hacer bloquear, si desbloquear (document.unlock()) pero en muchas ocasiones nos interesa bloquear el documento con el que estamos trabajando.
Desde Java se puede acceder al servicio de bloqueo de nodos de Alfresco, pero desde JScript (WebScripts) no se puede hacer bloquear, si desbloquear (document.unlock()) pero en muchas ocasiones nos interesa bloquear el documento con el que estamos trabajando.
Podemos usar varias soluciones: Sobrecargar o añadir métodos al objeto ScriptNode, exponer el servicio o crear una acción y llamarla desde JScript. En este caso vamos a implementar la exposición de un objeto locker en JScript a través de la forma Java-Backend.
Para esto hay que realizar dos ficheros, la definición del bean para que Rhino pueda tenerlo disponible y el código en Java que defina los servicios para JScript.
En primer lugar, el fichero de definición de bean (javascript-context.xml) puede ser algo así:
<?xml version='1.0' encoding='UTF-8'?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:util="http://www.springframework.org/schema/util" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-3.0.xsd"> <bean id="scriptLocker" class="es.omc.ae.javascript.ScriptLocker" parent="baseJavaScriptExtension"> <property name="extensionName"> <value>locker</value> </property> <property name="lockService"> <ref bean="LockService" /> </property> </bean> </beans>
Y el código en Java (ScriptLocker.java):
package es.omc.ae.javascript;
import org.alfresco.repo.jscript.ScriptNode;
import org.alfresco.repo.processor.BaseProcessorExtension;
import org.alfresco.service.cmr.lock.LockService;
import org.alfresco.service.cmr.lock.LockStatus;
import org.alfresco.service.cmr.lock.LockType;
/**
* Locker and Unlocker (Backend JScript)
*
* @author Fernando González (fegor [at] fegor [dot] com)
* @version 1.0
*
*/
public final class ScriptLocker extends BaseProcessorExtension {
private LockService lockService;
/**
* @param nodeRef
*/
public void unlock(ScriptNode scriptNode) {
LockStatus lockStatus = lockService.getLockStatus(scriptNode.getNodeRef());
if (LockStatus.LOCKED.equals(lockStatus)
|| LockStatus.LOCK_OWNER.equals(lockStatus)) {
this.lockService.unlock(scriptNode.getNodeRef());
}
}
/**
* @param nodeRef
*/
public void nodeLock(ScriptNode scriptNode) {
this.lockService.lock(scriptNode.getNodeRef(), LockType.NODE_LOCK);
}
/**
* @param scriptNode
* @param timeToExpire (in seconds)
*/
public void nodeLock(ScriptNode scriptNode, int timeToExpire) {
this.lockService.lock(scriptNode.getNodeRef(), LockType.NODE_LOCK, timeToExpire);
}
/**
* @param nodeRef
*/
public void readOnlyLock(ScriptNode scriptNode) {
this.lockService.lock(scriptNode.getNodeRef(), LockType.READ_ONLY_LOCK);
}
/**
* @param scriptNode
* @param timeToExpire (in seconds)
*/
public void readOnlyLock(ScriptNode scriptNode, int timeToExpire) {
this.lockService.lock(scriptNode.getNodeRef(), LockType.READ_ONLY_LOCK, timeToExpire);
}
/**
* @param nodeRef
*/
public void writeLock(ScriptNode scriptNode) {
this.lockService.lock(scriptNode.getNodeRef(), LockType.WRITE_LOCK);
}
/**
* @param scriptNode
* @param timeToExpire (in seconds)
*/
public void writeLock(ScriptNode scriptNode, int timeToExpire) {
this.lockService.lock(scriptNode.getNodeRef(), LockType.WRITE_LOCK, timeToExpire);
}
/**
* @param nodeRef
* @return
*/
public String getLockStatus(ScriptNode scriptNode) {
return this.lockService.getLockStatus(scriptNode.getNodeRef()).name();
}
/**
* @param nodeRef
* @return
*/
public String getLockType(ScriptNode scriptNode) {
return this.lockService.getLockType(scriptNode.getNodeRef()).name();
}
/**
* @param lockService
*/
public void setLockService(LockService lockService) {
this.lockService = lockService;
}
}
Ya solo queda usarlo, por ejemplo en JScript tenemos el objeto document, podemos hacer:
locker.nodeLock(document);
Para bloquearlo, o:
locker.unlock(document);
Para desbloquearlo posteriormente. También disponemos de los mismos métodos pero con un parámetro más para bloquear un número determinado de segundos.
En la versión 5 de Alfresco existen más métodos de este servicio pero he implementado los mínimos para que pueda funcionar desde versiones 3.4 y 4.x.
Enlaces de interés:
http://dev.alfresco.com/resource/docs/java/org/alfresco/service/cmr/lock/LockService.html
Cuando se instala Alfresco 5.0.2 y 5.1.EA, si esta instalación recoge los parámetros para español, se produce un error como el siguiente:
Caused by: org.alfresco.repo.node.
integrity.IntegrityException: 00270001 Found 1 integrity violations: Invalid property value:
Node: workspace://SpacesStore/
141296a2-92d5-4160-82ec- 828421bd8a4a Name: Rep. Dem.
Este error ya se resuelve en la incidencia https://issues.alfresco.com/jira/browse/ALF-21423 por Angel Borroy y lo que voy a explicar es, simplemente, como arreglarlo en el propio fichero WAR, de forma que, si instalamos de nuevo, no se produzca de nuevo el error.
Primero descomprimimos el fichero alfresco.war:
cd tomcat/webapps
mkdir fix
cp alfresco.war fix
cd fix
unzip alfresco.war
Descomprimimos el fichero alfresco-repository-5.0.x.x.jar (cambia las x por el número que tenga):
cd WEB-INF/lib
mkdir fix
cd fix
jar -xvf ../alfresco-repository-5.0.2.5.jar
Cambiamos el mensaje que falla en bootstrap-messages_es.properties:
vi alfresco/messages/bootstrap-messages_es.properties
[Buscar dentro de vi, p.e. /Rep\.\ Dem\.]
[Cambiar «Rep. Dem.» por «Rep\u00fablica»]
Nota: Se podría hacer de una vez sustituyendo en vi, pero eso os lo dejo a vosotros 😉
[Guardar con ESC+:wq]
Volvemos a crear el JAR (cuidado con los números de revisión), sobreescribimos el original y borramos este directorio:
jar cvf alfresco-repository-5.0.2.5.jar *
cp alfresco-repository-5.0.2.5.jar ../
cd ..
rm -rf fix
Volvemos a crear el WAR, creamos una copia del original, otra del nuevo, sustituimos el original y borramos el directorio de trabajo:
cd ../../
zip -r alfresco.war *
cd ..
cp alfresco.war alfresco.war-orig
cp fix/alfresco.war .
cp alfresco.war alfresco.war-fix
mv alfresco.war-orig ../../
mv alfresco.war-fix ../../
rm -rf fix
cd ../../
Reiniciamos el servicio de Alfresco y, si todo ha ido bien, arrancará sin problemas.
Nota: No olvidéis borrar previamente el despliegue (webapps/alfresco) así como el contenido del directorio work.
Eso es todo, solo me queda dar las gracias a Angel Borroy por su aportación en la resolución de este problema.
Más información:
https://issues.alfresco.com/jira/browse/ALF-21423

Estos errores vienen derivados principalmente de las nuevas configuraciones de red implementadas en Windows, a partir de la versión 7 en realidad, y que en su versión 10 han sufrido un gran cambio.

Hace unos días, recibí un correo electrónico donde se me avisaba de un error de Alfviral cuando se intentaba actualizar un documento desde Share en la versión 4.2.
Al parecer, en esta versión se usa un nuevo sistema de actualización asíncrona y cuando se actualiza un documento se produce un borrado de nodo para crear otro que es el actualizado. El sistema de eventos salta con cada paso por lo que hay que verificar antes de nada que el nodo sigue todavía «vivo» y no ha sido borrado por el propio sistema de actualización. Esto, curiosamente no pasa en el contexto del Explorer (Alfresco).
En resumen, he re-factorizado algo más el código, he arreglado el problema y he reorganizado el proyecto tipo all-in-one como dos submódulos de repositorio y otro para share, así creo que está más claro y es más sencillo de instalar.
La nueva revisión se puede descargar desde: https://github.com/fegorama/alfviral/releases/tag/v1.3.2-SNAPSHOT
{kind=link}
{kind=link}
{kind=link}